Cloud Native - Auto Scaling

Auto Scaling in Cloud Native Applications
- In the world of cloud-native applications, auto scaling is a critical practice that ensures applications can dynamically adjust to varying loads while maintaining performance and cost-efficiency.
- Auto scaling automatically adjusts the number of computing resources (e.g., servers, containers, etc.) allocated to an application based on demand.
- It is a key component of cloud-native architectures, helping businesses scale efficiently without manual intervention.
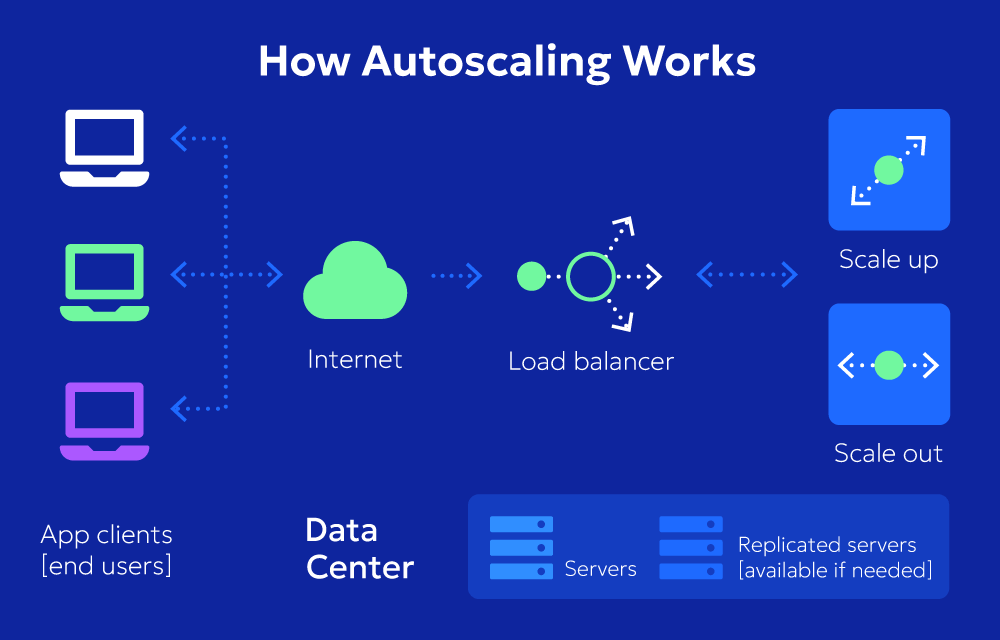
What is Auto Scaling?
- Auto scaling is the process of automatically adjusting the capacity of cloud resources, such as virtual machines (VMs), containers, or storage, based on real-time demand.
- It allows applications to scale up (add more resources) during peak usage times and scale down (remove excess resources) during low traffic periods, ensuring cost savings and optimal performance.
Types of Auto Scaling
Reactive Auto Scaling
- Reactive auto scaling responds to changes in demand by increasing or decreasing resources based on real-time metrics.
- This scaling happens immediately when resource usage crosses a predefined threshold, ensuring the application can meet increasing traffic demands and minimizing downtime.
- For example, scaling a web server cluster up when the CPU utilization reaches 80%.
Scheduled Auto Scaling
- Scheduled auto scaling allows you to predefine scaling actions based on known patterns of resource usage.
- This approach is useful when you know traffic will spike at specific times (e.g., during holidays or special events).
- Scheduled scaling can increase resources at a set time and scale down when no longer needed.
Predictive Auto Scaling
- Predictive auto scaling uses machine learning or statistical analysis to anticipate future demand based on historical data.
- This method can automatically adjust resources before the demand hits its peak, reducing response times and preventing over-provisioning.
- Predictive scaling can significantly improve resource optimization and performance.
Horizontal vs. Vertical Scaling
Horizontal Scaling (Scaling Out/In)
- Horizontal scaling involves adding or removing instances of a resource, such as adding more containers, virtual machines, or nodes to a system.
- It is the most common form of auto scaling and is well-suited for cloud-native applications, as resources can be distributed and managed more efficiently.
- Horizontal scaling helps to increase availability and fault tolerance by spreading the workload across multiple resources.
- Example: Adding more container replicas in Kubernetes to handle a growing number of requests.
Vertical Scaling (Scaling Up/Down)
- Vertical scaling involves increasing or decreasing the resources of a single instance, such as adding more CPU, memory, or disk space to a virtual machine or container.
- While vertical scaling is easier to implement, it may not be as efficient or fault-tolerant as horizontal scaling.
- It also has limitations, as there is a ceiling on how much you can scale a single resource.
- Example: Adding more CPU cores to a virtual machine when resource demand increases.
Metrics for Auto Scaling Configuration
When configuring auto scaling, you typically rely on various metrics to trigger scaling actions. These metrics can include:
CPU Utilization: Monitors the percentage of CPU usage to trigger scaling actions (e.g., scale up if CPU utilization exceeds 80%).Memory Usage: Tracks the percentage of memory usage to determine scaling actions.Network Traffic: Measures the volume of inbound and outbound network traffic to ensure that there are enough resources to handle the load.Disk I/O: Measures input/output operations on disks, ensuring that applications are not bottlenecked by storage.Request Queue Length: Increases resources when the number of pending requests exceeds a threshold.Custom Application Metrics: Any custom metric that is specific to the application’s workload, like response times or transactions per second.
Kubernetes Auto-scaling (HPA and VPA)
Horizontal Pod Autoscaler (HPA):
- Kubernetes offers HPA to scale the number of pods based on resource usage, such as CPU or memory utilization.
- HPA automatically increases or decreases the number of pod replicas depending on the demand.
- It is useful in microservices architectures to ensure that the right amount of resources are allocated to each service.
- Example: If the CPU utilization of a pod exceeds 80% for a certain period, HPA will create additional pod replicas to handle the load.
Vertical Pod Autoscaler (VPA):
- While HPA scales the number of pods, VPA adjusts the resource requests (CPU, memory) for individual pods based on their usage.
- VPA helps to ensure that each pod has the right amount of resources allocated to it for optimal performance.
- It can scale up a pod’s resources when it’s consistently under high demand but can also scale down when demand is low.
- Example: If a pod is constantly using 90% of its allocated memory, VPA will increase the memory allocation for that pod.
KEDA - Kubernetes Event-Driven Autoscaling
- KEDA (Kubernetes Event-Driven Autoscaler) extends the auto-scaling capabilities in Kubernetes by allowing autoscaling based on external event triggers.
- It enables scaling based on a wide variety of event sources, such as Azure Queue Storage, AWS SQS, Kafka, and more.
- KEDA can scale applications not just based on CPU or memory utilization but also according to custom events like message queue lengths or scheduled events.
- One unique feature of KEDA is its ability to scale down to zero when there is no workload. This is particularly useful for event-driven architectures, where resources should only be utilized when necessary and saved when idle.
- Example: A microservice listening to a message queue can scale up when a new message is added but scale down to zero when there are no new messages.
Conclusion
Auto scaling plays a crucial role in ensuring that cloud-native applications maintain optimal performance while minimizing resource waste. With the right scaling techniques—whether reactive, scheduled, or predictive—and leveraging horizontal or vertical scaling, organizations can ensure that their applications are responsive to changes in demand.
Using Kubernetes tools like HPA, VPA, and KEDA allows developers to efficiently manage scaling in a cloud-native environment. Understanding and implementing these scaling strategies not only improves performance but also ensures cost-effectiveness and resource optimization.